Introduction
The engineering challenges of Agent frameworks are giving rise to a new generation of solutions—Harness. This article dissects the design philosophies of three major frameworks: OpenClaw, Hermes, and Claude Code, revealing the seven engineering gaps that Agents must cross from proof of concept to production deployment. Only when model capabilities are deeply integrated with engineering systems can we truly understand why Harness is the key factor in the success or failure of Agents.
Harness has recently gained some attention, but it differs from OpenClaw and Hermes in that it lacks a fully realized description; it was created for the stable execution of Agents.
The articles available on the platform often seem either too abstract or too fragmented.
To understand Harness, one must not only grasp the overarching concepts but also refer to currently operational Agent frameworks like Claude Code, OpenClaw, and Hermes to bring it back to the engineering context.
Background of Harness
Thanks to the recent developments in Agents, including the successive releases of OpenClaw and Hermes, as well as the source code leak of Claude Code, the global understanding of the Agent development paradigm has reached a new level.
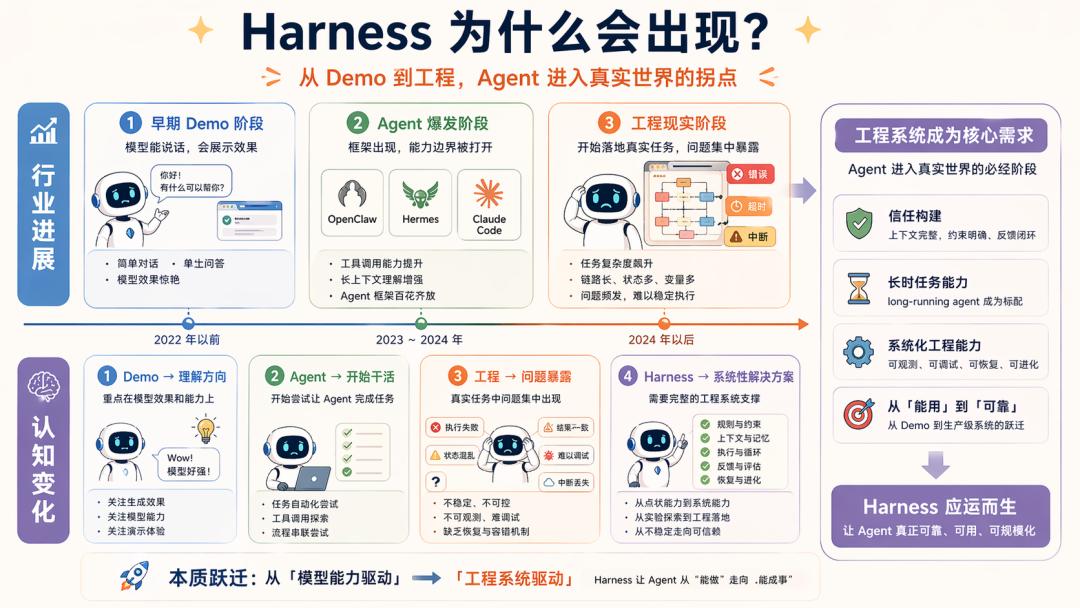
Given this foundation, we cannot assume that the term Harness has suddenly become popular; it has emerged because the engineering issues have finally become apparent as Agents begin to perform real tasks.
As Martin Fowler defined in an article in April 2026, Harness Engineering is a model for building trust around coding Agents, focusing on context, constraints, feedback loops, and engineering structure to gradually allow humans to delegate tasks to Agents.
Anthropic itself refers to Claude Code as an excellent harness in its official engineering articles, further discussing harness design in long-running Agents and application development.
Thus, at this stage, Claude emphasizes not just its model strength but also its engineering capabilities. However, we can see that domestic frameworks can also achieve significant improvements simply by switching to the Claude model.
I believe Claude’s strength lies primarily in coding, and domestic engineering capabilities may not necessarily be inferior.
Today, as we explore the culmination of engineering paradigms represented by Harness, we must move beyond merely discussing prompt engineering. Context engineering seems insufficient to encompass its meaning; the current question has returned to:
Why do Agent frameworks like OpenClaw, Hermes, and Claude Code ultimately develop a complete engineering system? And why does this system increasingly resemble the key to the success or failure of Agents?
Models and Engineering
Over the past two years, major model companies have primarily focused on the Agent ecosystem: semantic understanding, visual generation, long-context tool invocation, multimodal computer operations, and browser operations.
There is an industry perspective that suggests designing for the next six months, as models will become stronger, thereby reducing engineering costs. This is a significant assumption: as long as models continue to improve, applications will naturally emerge.
However, the reality is that once the stability of long-context and tool calling improves, the Agent line indeed becomes much easier to work with.
The problem is that a strong model does not equate to stable engineering. There are always boundaries that can be crossed, including: models may still miscall or be unstable in tool invocation; models can understand complex inputs but struggle with prolonged tasks; just because a model can write code does not mean it knows if it is correct.
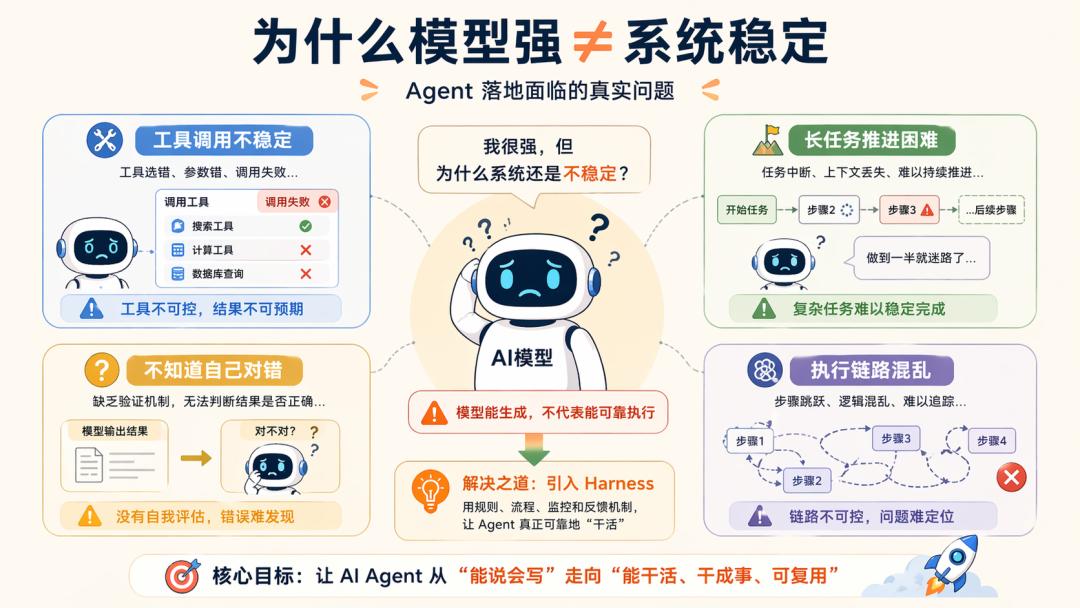
The significance of engineering architecture lies in enabling Agents to complete tasks reliably. As a result, from 2025 to 2026, the focus of Agent discussions began to shift noticeably: previously, people discussed how to write prompts, then how to feed context, and now the real discussion is about what system capabilities are still needed after the Agent is operational.
This is the entire context in which Harness has emerged.
What is Harness?
Currently, there are many definitions of Harness in the market, the most understandable being:
Model = Brain Harness = Body + Workbench + Operating Procedures + Supervision Mechanisms
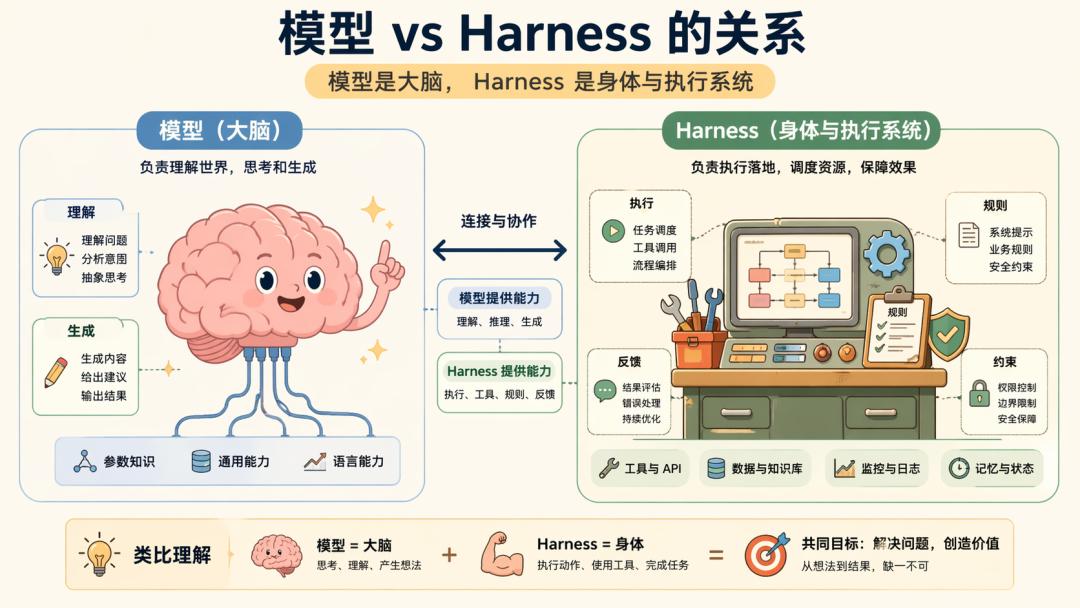
First, regardless of whether this description is rigorous, I find it challenging to elaborate because Harness is an engineering product. Engineering products are not merely SDKs or prompt tricks; they are a collection of various hard problems we tackle in projects. Thus:
Harness is the system that transforms model capabilities into continuous, stable, and verifiable product capabilities.
At its core, it consists of many rules, constraints, and designs.
Prompt → Context → Harness
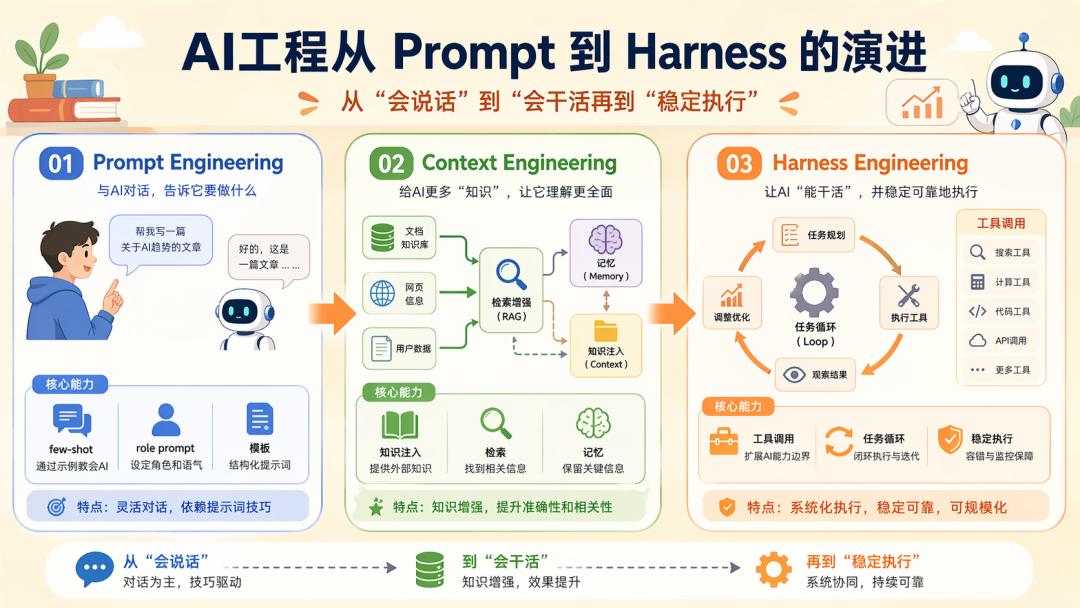
As mentioned earlier, Harness is a product of engineering practice in the process of developing Agents. Therefore, Harness did not emerge from thin air; it is an evolution of previous engineering products: Prompt Engineering and Context Engineering.
Context Engineering is an extension of Prompt Engineering, and Harness is the result of their two evolutions.
1. Prompt Engineering
Prompt Engineering directly addresses how we should interact with models, making it the simplest and most effective approach. Early on, the focus was on: few-shot prompts, role prompts, CoT output format constraints, and prompt templates.
The essence of this layer is translating industry know-how into natural language instructions.
It is worth noting that regardless of how engineering evolves, it will ultimately return to prompts. Thus, many believe that current engineering optimizations are still extensions of Prompt Engineering, which is not incorrect.
2. Context Engineering
As tasks became more complex, writing a good prompt alone was no longer sufficient, leading to the emergence of Context Engineering: which private knowledge to include, which historical conversations to retain, how to compress long contexts, how to perform retrieval, and how to prevent the model from forgetting or being overwhelmed by information.
At this stage, the system is no longer simply responding according to SOP but begins to answer based on combined materials, with the core revolving around CoT.
It should be noted that the essence of Context Engineering is Data Engineering, and those truly engaged in production-level AI applications often find themselves in a paradox: spending 80% of their time on data, leading to doubts about the connection between this tedious work and the glamorous AI.
3. Harness Engineering
As Agents began to evolve beyond simple Q&A, they started to: invoke tools, run code, break down tasks, view pages, write documents, execute multi-turn cycles, and manage sub-Agents, interruptions, recovery, testing, and acceptance.
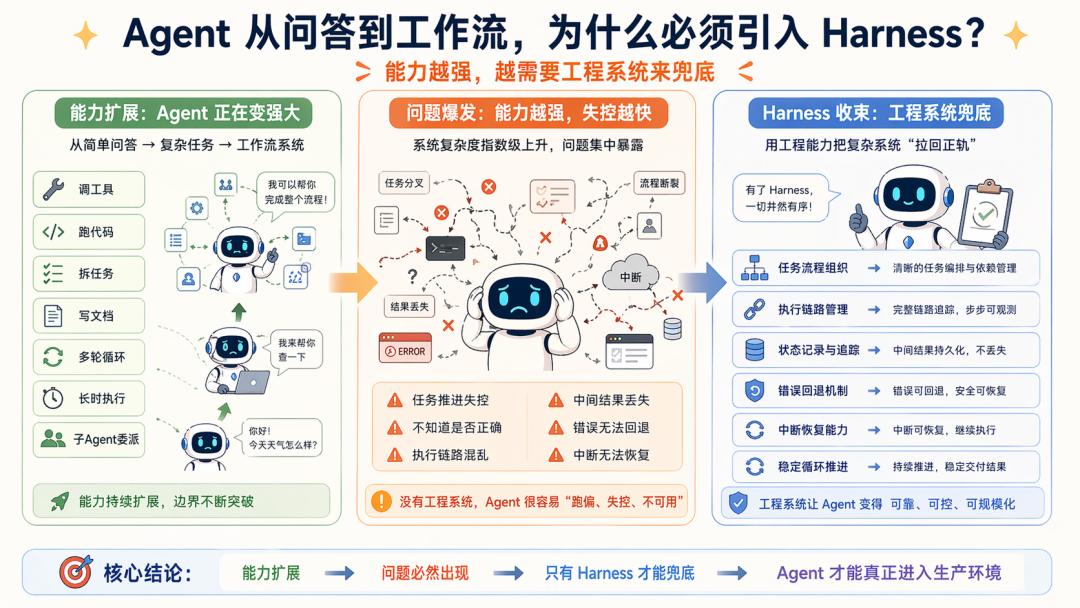
As previously mentioned, the emergence of Agents aims to address the heavy maintenance work caused by insufficient workflow generalization.
However, due to increased engineering complexity, Context Engineering alone is no longer sufficient. The questions have shifted from data-related issues to: how to sustain task progression without losing control, how models can verify their correctness, how to organize execution chains, how to retain intermediate results, how to backtrack errors, and how to resume tasks.
At this point, Harness naturally emerges as a comprehensive solution forced out by engineering realities:
When Agents transition from Q&A to workflows and from single-turn to long-chain tasks, a complete solution emerges from engineering necessity.
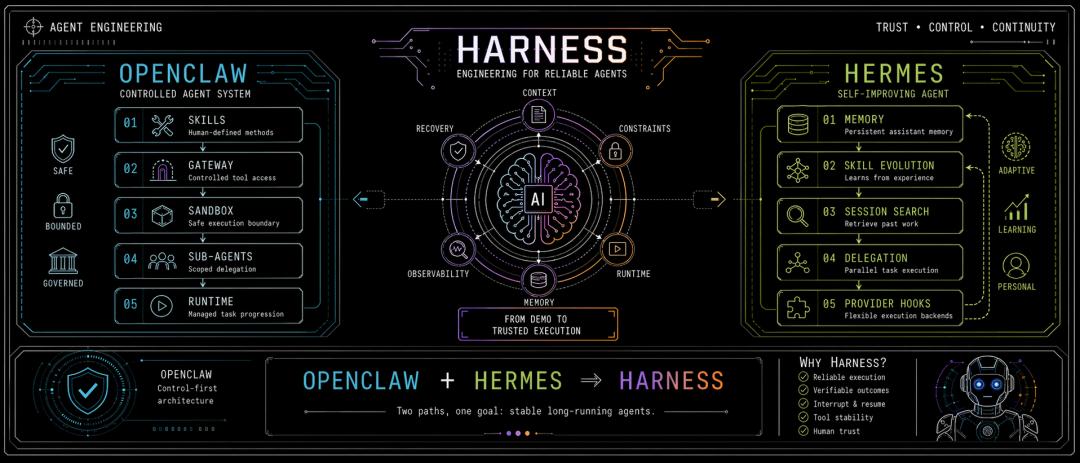
OpenClaw, Hermes
As previously mentioned, Harness has become somewhat abstract because we tend to detach it from real frameworks.
To truly discuss it, we must return to the Agents themselves and place Harness back within OpenClaw, Hermes, and Claude Code, making it much more concrete.
These three frameworks represent three typical engineering orientations for Agents:
1. OpenClaw: First Control the Agent
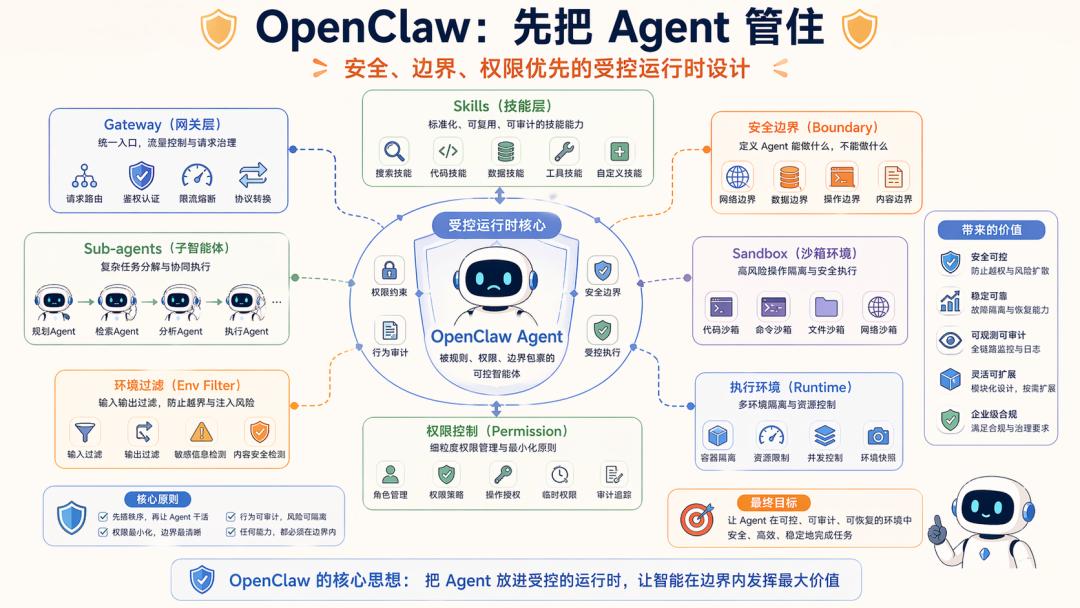
The official documentation and repository of OpenClaw clearly emphasize controlled runtime.
It delineates Skills, Gateways, security boundaries, Sub-agents, and Sandboxes clearly.
For instance, the official Skills documentation states that OpenClaw uses AgentSkills-compatible skill folders, with each skill directory containing SKILL.md, and filtering based on environment, configuration, and dependencies during loading.
Its security documentation repeatedly emphasizes that OpenClaw currently assumes a personal assistant security model, meaning deployment within a trusted boundary rather than unrestricted production.
The system engineering goal behind this design is clear: first organize permissions, boundaries, roles, skills, and execution environments before allowing the Agent to perform tasks.
OpenClaw aims to become a standard enterprise Agent, so its engineering direction is also clear:
How to enable the Agent to execute tasks safely, stably, and in a controlled manner?
However, it must be noted that this framework is still immature, especially in multi-user collaboration, making it challenging to implement effectively, but that does not imply its direction is wrong.
2. Hermes: First Let the Agent Learn
Hermes presents a different flavor in its README.
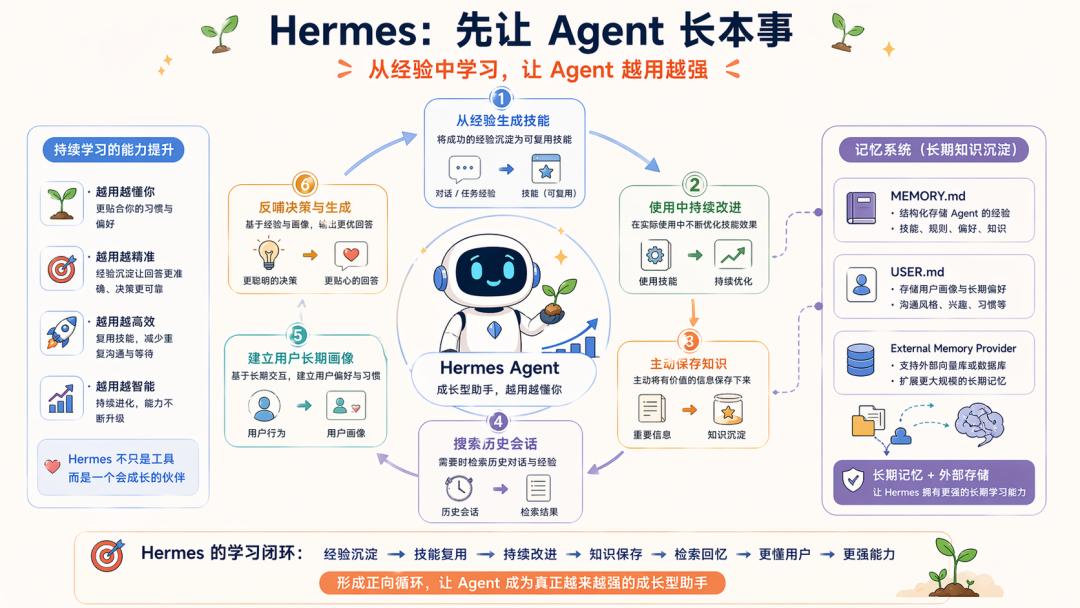
It defines itself as “the self-improving AI agent,” directly stating its core capabilities as a learning feedback loop: creates skills from experience, improves them during use, nudges itself to persist knowledge, searches its own past conversations, and builds a deepening model of who you are across sessions.
Hermes’s official documentation also provides eight types of external memory providers and clarifies that built-in MEMORY.md / USER.md always exist, while only one external provider can be enabled at a time to avoid schema bloat and conflicts.
This is why I often say Hermes is clever: it lacks the ambition of OpenClaw, temporarily focusing on enabling individual users, iterating based on OpenClaw’s pain points. Its engineering goal is also clear:
First, allow the Agent to learn and grow from experience, and gradually add boundaries and governance.
Hermes aims to make Agents stronger the more they are used, evolving into long-term assistants.
3. Claude Code
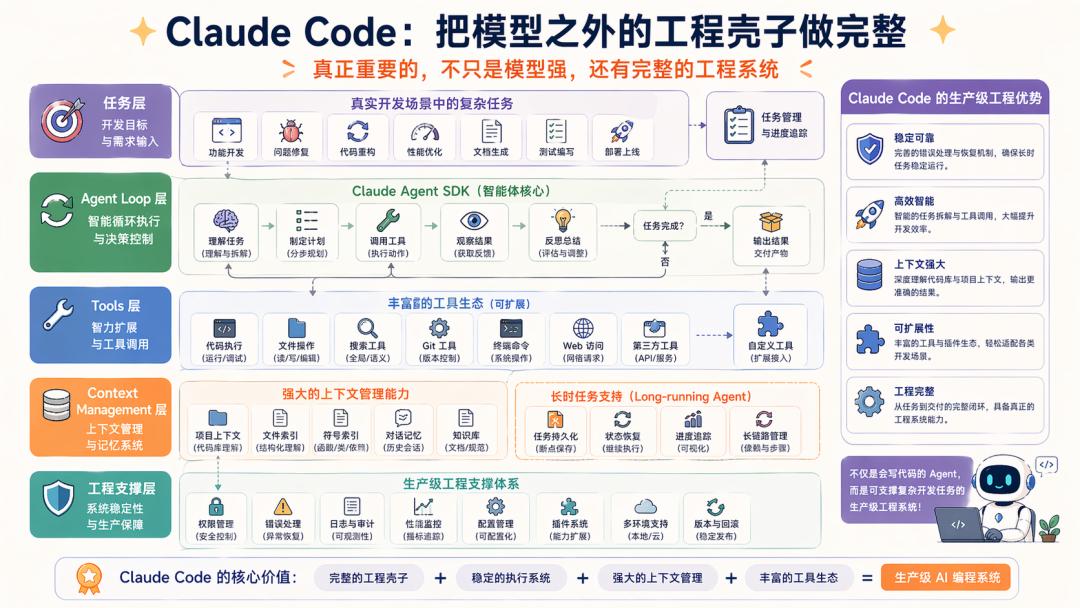
Claude Code operates in a completely different scenario; it is a production-level application, no longer just “an agent that can code.”
Anthropic has now opened the capabilities derived from Claude Code as the Claude Agent SDK, explicitly stating that this SDK provides the tools, agent loop, and context management behind Claude Code.
Moreover, Anthropic has published several engineering articles specifically discussing how to design harnesses for long-term Agents and optimize harnesses in application development scenarios. Claude Code is considered an excellent harness in itself.
This means that the value of Claude Code lies not just in its strong model but also in:
It has developed an entire engineering framework beyond the model that is significantly important.
Thus, if one truly wants to learn about Harness, logically, Claude Code serves as the best example. However, we cannot access its complete code, and in terms of complexity, OpenClaw might be the optimal solution.
Dissecting Harness
If we truly want to dissect Harness, I believe there are at least seven layers.
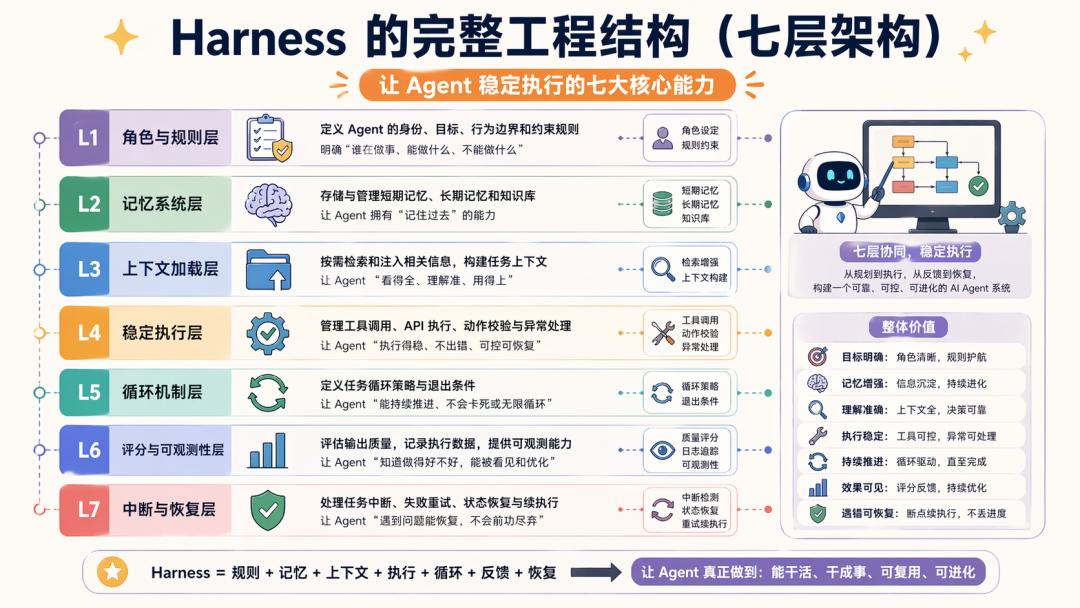
Here, apart from my previous understanding of AI applications, each layer can be grounded in OpenClaw, Hermes, and Claude Code.
Layer 1: Roles and Rules
When a model receives a task, the first thing is not to invoke tools but to clarify: who it is, whether it is responsible for planning, execution, or acceptance, what its boundaries are, and how to handle uncertainties.
As long as this is established, all subsequent actions will have a basic level of control.
OpenClaw excels in this regard: Skills are written by humans, rules are set by humans, boundaries are established by the system, and the Agent primarily executes within the framework.
Hermes is more flexible here: it has system prompts, role definitions, and runtime rules, but it prefers to delegate some judgment capabilities to the Agent itself, meaning it does not concern itself with Skills Plaza, such as when to generate new Skills or update old ones.
Claude Code is closer to tools as processes: Anthropic continuously emphasizes the agent loop, context management, and long-task initializers/coding agent division, which essentially embeds roles and rhythms into the system.
Thus, the first step in creating Harness is to determine your current working identity.
Layer 2: Memory System
Once a task becomes lengthy, it inevitably generates many intermediate results: sub-tasks broken down, discussed solutions, current progress, user preferences, historical errors, and successful experiences.
No context is too long to waste, leading to differences in engineering across frameworks:
OpenClaw adopts a restrained approach to memory, essentially closer to replaceable capabilities, meaning it implements the basics, and you can replace it according to your situation.
Hermes, on the other hand, has developed a complete memory system: built-in MEMORY.md, USER.md, supplemented by external memory providers, and session search.
The official documentation clearly states that built-in memory is always enabled, and only one external provider can exist simultaneously, adhering to the principle: don’t mess around, just use mine.
Thus, users often feel that OpenClaw frequently ignores what was said yesterday, while Hermes also exhibits this behavior but provides an explanation.
Claude Code emphasizes another approach in its official articles: in long-term tasks, clear artifacts and handoffs are crucial for the next session to continue.
Therefore, the essence of the memory system in engineering is to ensure that the task process leaves traces, allowing the system to pick up where it left off.
Layer 3: Context Loading Mechanism
What exactly should the model see? This is a challenge all AI applications face, and there is a sense that no solution is optimal.
In real Agent scenarios, the model will have access to an increasing amount of information: roles and rules, historical dialogues, memory, skills, tool results, and current tasks.
The problem arises: it is not a lack of information but an overload of it.
OpenClaw’s Skills loading logic essentially serves as a context filter: screening based on environment, configuration, and dependencies.
Hermes takes a different route: its session search does not dump historical raw text but retrieves and processes it first; it also supports context engine plugins to replace built-in context compressors.
Thus, determining how to provide the model with only the most necessary information in each round is, in my view, the most challenging aspect of model engineering. This further leads to issues regarding private data loading: if this layer is not handled well, the system will face problems on both ends: seeing too little, akin to amnesia, or seeing too much, leading to confusion.
Layer 4: Stable Execution
Agents, or the ReAct framework, represent the framework we selected in the model era, marking the point where Agents begin to take action. Thus, how tools receive commands, how files are executed, how pages are read and written, how code is checked, and how results are collected are all engineering concerns, as they rely on third parties and are prone to issues.
OpenClaw is a typical example of a safety-first runtime.
Hermes resembles a flexible execution backend, with its official README stating it can run locally, on VPS, GPU clusters, or serverless environments with near-zero idle costs.
Thus, the goal of this layer of Harness is to transform language judgments into stable, real actions. Without this layer or if it is poorly executed, frequent errors will occur.
Layer 5: Effective Loop
Ordinary chatting represents AI 1.0; since DeepSeek, we have been pursuing multi-turn Q&A. Agents inevitably enter loops due to the complexity of the problems they handle: understanding tasks, deciding the next execution step, reading results, and judging the next step, continuing until closure.
OpenClaw’s multi-Agent, skills, and runtime all revolve around advancing these loops.
Hermes embeds delegation, skills, memory, search, and provider hooks within this loop.
As mentioned earlier, more intelligence will inevitably consume more tokens; the issue with Agent loops lies here: will they waste tokens and time without substantial progress?
In engineering systems, the concern has always been not the loop itself but whether money is spent without results.
Layer 6: Scoring and Observability
One of the major issues with models is not their inability to perform tasks but rather that they often believe they have completed them.
On the surface, code may be written, pages rendered, and replies sent, seemingly closing the loop. However, upon verification, many aspects may not connect at all.
Thus, in system engineering, we embed points at every critical node to establish scoring and observability mechanisms.
In other words, the system cannot solely rely on the model reporting, “I have completed it,” but must be able to see through tests, logs, page verifications, operational metrics, manual reviews, and benchmarks what it has done, to what extent, and the quality of the results.
How to establish trust in the results of Agents cannot rely solely on the model’s self-reporting; it must have external feedback mechanisms.
Anthropic’s harness design articles also discuss similar issues: to improve long-term application development performance, having an agent loop is insufficient; a stronger environmental and feedback framework is also needed.
OpenClaw’s strategy here is institutionalized: constraining results through rules, sandboxes, and controlled execution.
Hermes, on the other hand, focuses on learning loops: gradually consolidating execution results, error paths, and successful experiences into Skills or Memory.
Thus, the goal of this layer is to prevent models from blindly giving themselves high scores.
Layer 7: Interruption and Recovery
This layer is key to engineering control.
We are accustomed to completing tasks in one go, but the real world does not operate that way. Additionally, when designing SOPs/Workflows, humans struggle with boundary backtracking, and models face similar challenges.
Thus, during repeated cycles, whether the overall SOP will backtrack and how to do so becomes critical.
This layer often seems tedious but becomes especially important when running, as you will find that tasks can indeed be interrupted, time out, switch sessions, or fail and require retries.
As for how to resolve this:
Hermes uses MEMORY, USER, session search, and external providers to systematize continuity.
OpenClaw’s approach leans more towards controlled processes and traces.
Therefore, in engineering systems, the final challenge is how to reconnect interrupted tasks.
At this point, I believe we have clarified the discussion, and finally, let’s go through Harness using OpenClaw as a concrete example.
OpenClaw: Understanding Harness
Having discussed many concepts regarding Harness, what does this so-called Harness look like when an Agent framework is actually operational? Let’s continue with OpenClaw, which I am more familiar with.
Layer 1: MCP/Toolchain
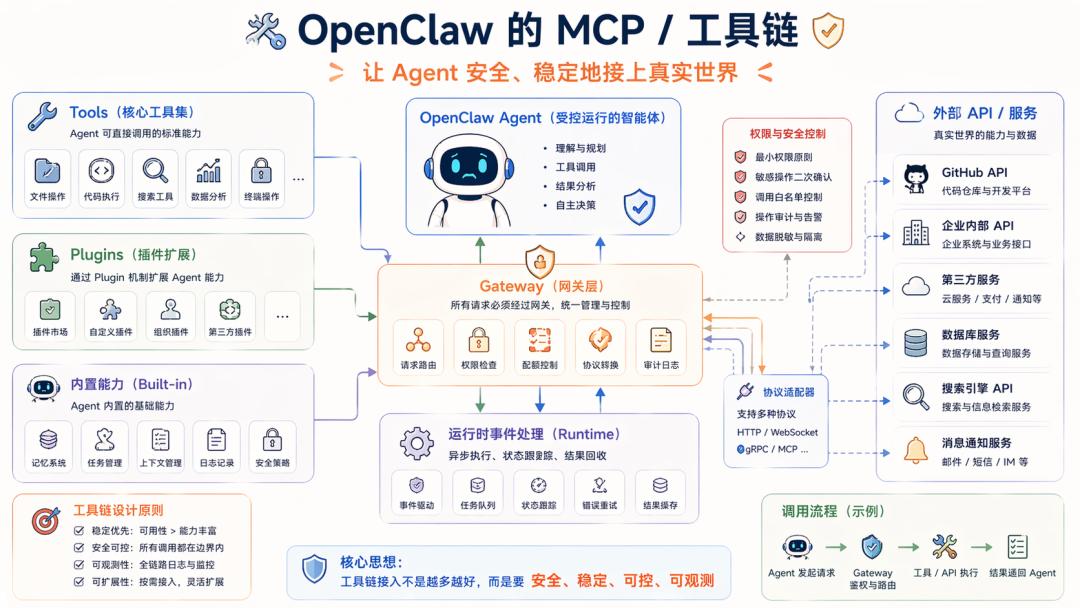
When people mention OpenClaw, the first reaction is often Skills, which is correct; Skills are indeed core and serve as the entry point for interaction with the Agent.
However, from the perspective of Harness engineering stability, the entire MCP/toolchain layer is crucial. Once an Agent starts working, it must resolve how to safely and stably connect to the real world.
Skills serve as method stabilizers, preventing the model from diverging too much; the MCP/toolchain represents the capabilities themselves.
If Skills encounter issues, the system may behave erratically; if Tools fail, the entire process breaks, and this is dependent on third parties, which are inherently prone to problems, including API changes, permission shifts, plugin failures, and parameter variations.
Thus, the engineering system must first clearly define capability specifications. OpenClaw exemplifies this by placing Tools, Plugins, Gateways, and external capabilities into a clearly bounded system, aiming to ensure:
Can the model stably invoke tools within a constrained capability plane?
For instance, a common scenario is when an external API fails.
Without engineering control, the model may not distinguish whether it misunderstood or if the upstream interface is down.
In this scenario, the model may behave foolishly, increasing output force and looping continuously, wasting tokens and time; in extreme cases, it might even inform downstream: I’ve got it done…
At this point, the value of Harness becomes apparent.
Taking OpenClaw as an example, the correct handling approach is to treat API call failures as runtime events.
Currently, OpenClaw’s strategy involves managing tool calls within a runtime plane governed by a Gateway. The specifics are too numerous to elaborate here…
Layer 2: Skills
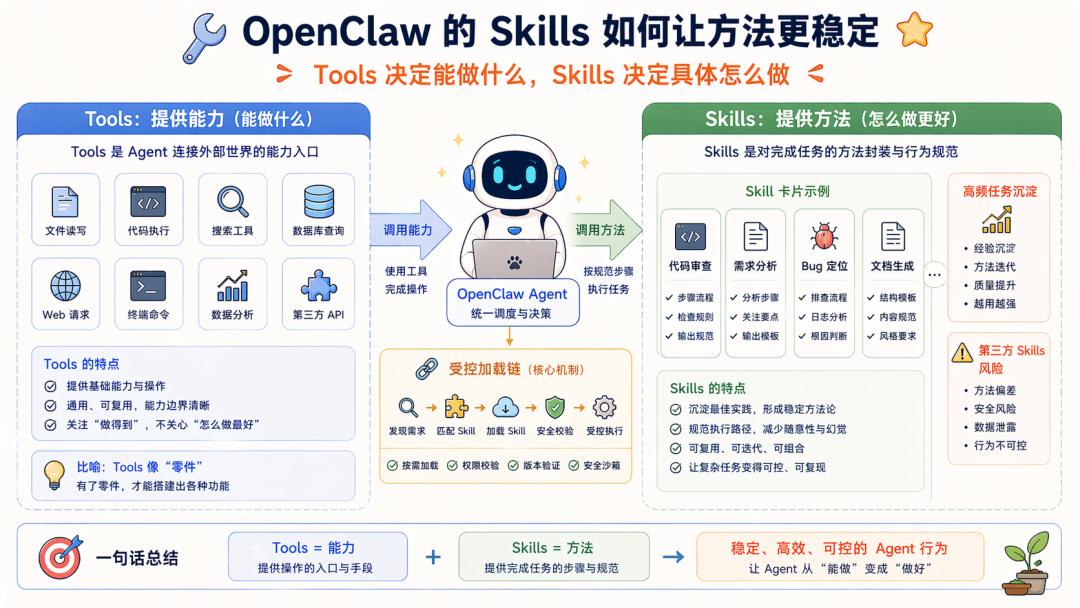
Once the capability foundation is established, we turn to Skills, which are crucial. Tools determine what can be done; Skills determine how to do these tasks specifically.
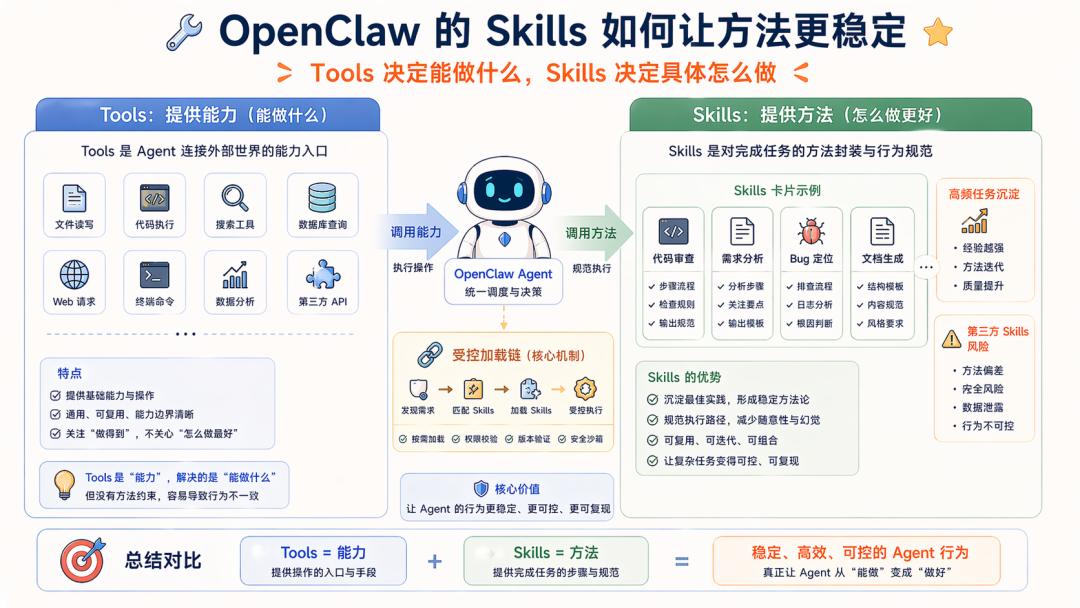
Skills are inherently advantageous, as their on-demand loading can partially alleviate tool invocation errors. Their Workflow prompts further enhance stability by consolidating high-frequency task methods.
However, in platform-type Agents like OpenClaw, the Skills issue is also apparent: Skills may originate from third parties, and Skills inherently enter the prompt construction chain, making the model fragile and easily polluted by malicious or low-quality prompts. Once the Skill mechanism is compromised, the Agent’s method layer may become distorted.
Thus, in system engineering, the Skills mechanism should be classified under Harness. We have previously implemented similar systems.
Now that Skills have been implemented at the foundational level, we are less concerned about the significance of Skills. For OpenClaw, the focus is on:
How to ensure that this open mechanism for Skills does not drag the entire system down.
Here, various rules are employed for constraints. You will find that engineering systems generate numerous constraints. For instance, OpenClaw emphasizes that third-party Skills are inherently untrustworthy.
Furthermore, OpenClaw must also implement further fallback strategies. The approach here is to place Skills within a controlled loading chain; for example, plugin Skills are only low-priority paths, and Skills with the same name will be bundled/managed/agent/workspace Skills will take precedence; skill discovery for workspaces and extra directories only accepts parsed real paths that remain within the configuration root directory to avoid path traversal and arbitrary escape.
Many fallback strategies are employed here, but we will not delve into the details…
Layer 3: Runtime
The subsequent issue is not about tool and skill invocation but rather how to sustain the execution of complex tasks.
OpenClaw enters a loop when executing complex tasks: first understanding the problem, then deciding the next step, invoking tools, reading files, running code, checking results, and determining what to do next, continuing until the task is genuinely closed.
However, the reality is that bugs frequently occur. Once the model enters a long task, various issues may arise: it might prematurely conclude the task, claiming completion when it is not; it might loop back to the start, repeatedly invoking the same tool.
Thus, from an engineering perspective, we hope to have a mechanism to clarify: how far along the current task is, who should do the next step, when to continue, when to pause, and when to revert.
OpenClaw’s Runtime assumes this responsibility, attempting to organize the Agent’s actions from a series of scattered actions into a coherent process that can genuinely advance the task.
This Runtime includes the entire project’s observability and interruption/retry logic, which is quite complex, so we will not elaborate further…
However, perhaps you now have a deeper understanding of what Harness is.
Conclusion
Harness is not a module but a path—a methodology that emerges from tackling hard problems.
You can clearly see how a Demo Agent progresses to OpenClaw: it begins by merely invoking tools; then realizes tools are unstable and adds rules; next, it finds rules insufficient and incorporates Skills; it then discovers Skills are inadequate and adds Runtime and Workflow; finally, it recognizes tasks may falsely appear complete and must supplement scoring and observability; and ultimately, it understands that tasks can be interrupted and must enhance recovery capabilities.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.