Recently, Anthropic’s Claude Code has taken the AI programming community by storm!
This AI assistant, capable of reading code, modifying it, and running tests in the terminal, has developers exclaiming, “This is the future.”
Social media is buzzing with comments like “Claude Code outperforms Cursor, Codex, Antigravity” as everyone speculates on OpenAI’s next big move with GPT-5.3. Today, OpenAI revealed two major updates on X platform:
- Agent Loop Architecture Unveiled: The Inner Workings of Codex’s ‘Brain’
- PostgreSQL Extreme Architecture: One Master Database Handling 800 Million Users
This powerful combination is impressive. Let’s break down what OpenAI has in store.
Agent Loop
How Codex’s ‘Brain’ Works
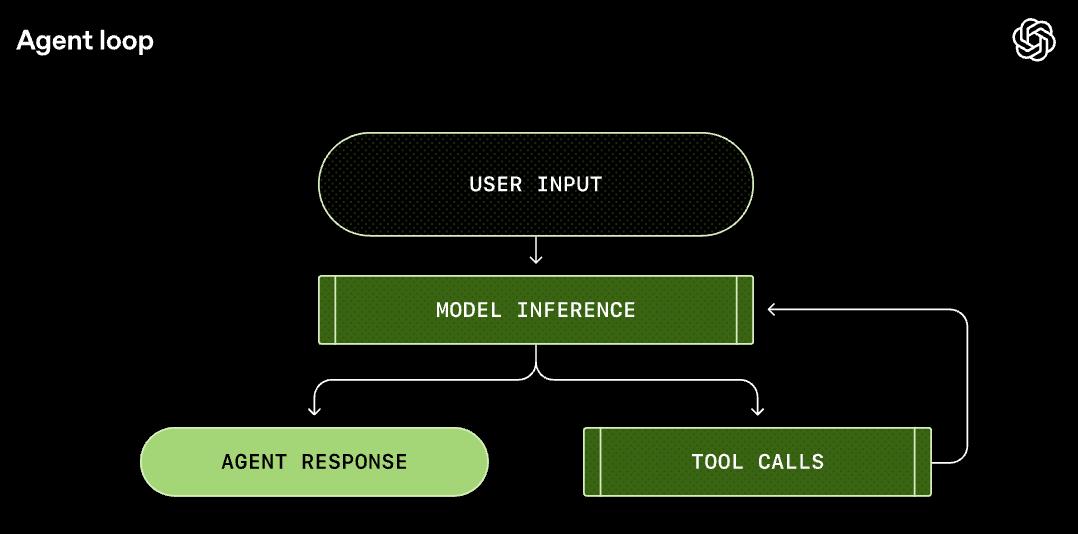
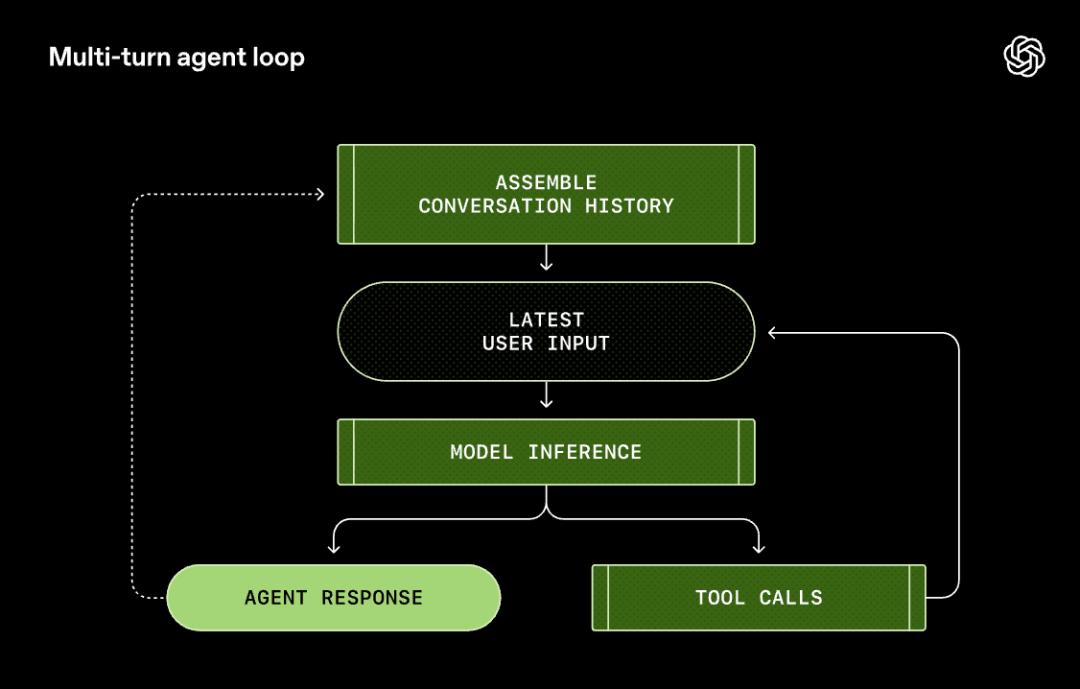
What is Agent Loop?
If you have used Codex CLI, Claude Code, or similar CLI terminal tools, you may wonder:
How does it know what I want to do? How can it read files, write code, and run commands on its own?
The answer lies in something called Agent Loop.

In simple terms, the Agent Loop acts like a “conductor,” responsible for creating a perfect closed loop between “user intent,” “model brain,” and “execution tools.”
This is not just a simple “Q&A”; it is a working system that includes “observe-think-act-feedback.”
Let’s break down how a true AI Agent operates.
How a Complete Agent Loop Works
Let’s illustrate with a specific example.
Suppose you input in the terminal: Add a diagram to the project’s README.md.
Step 1: Constructing the Prompt
This is like sending a work order to the brain.
Codex doesn’t just pass your words to the model; it first constructs a carefully designed “Prompt”:
- Who am I (System): Tell the model who it is and what it can do.
- What tools do I have (Tools): What tools can be invoked (like shell commands, file operations).
- Context: What directory is currently in use, what shell is being used.
- User instruction: Add a diagram to README.md.
This is akin to sending the model a detailed work email instead of just saying, “Help me.”
Step 2: Model Inference
At this stage, the brain starts to work.
Codex sends this Prompt to the Responses API, and the model begins to think:
“The user wants to add a diagram; I need to check what the current README looks like…”
Then the model decides: Call the shell tool to execute cat README.md.
Step 3: Tool Call
Codex receives the model’s request, executes the command locally, and reads the content of README.md.
This is like the hands and feet starting to move.
Step 4: Result Feedback
The terminal outputs the content of README.md.
At this point, the process isn’t over. Codex appends the command output to the Prompt and sends it back to the model.
Step 5: Looping
The model sees the content of README and infers again:
It may generate a Mermaid diagram or write an ASCII graphic… then call the tool to write to the file.
This loop continues until the model deems the task complete, outputting a message, “I’m done.”
It is not answering questions; it is solving problems.
Why is this important?
You might say, “Isn’t this just making a few API calls?”
But it’s not that simple.
Traditional LLM applications are “one question, one answer”: you ask, it answers, and that’s it.
But the Agent Loop transforms AI into an independent worker.
It plans its own path (Chain of Thought).
It checks for errors (Self-Correction).
It verifies results (Feedback Loop).
This is the true ‘AI Agent.’
And the Agent Loop is the bridge that allows AI to leap from “chat companion” to “independent worker.”
Performance Optimization
Two Key Technologies
OpenAI shared two hardcore optimizations that address two major pain points in Agent development:
Pain Point 1: Exploding Costs
Every time the Agent Loop runs, it must resend the previous conversation history (including lengthy error messages and file contents) to the model.
The longer the conversation, the higher the cost. Without optimization, costs grow quadratically.
Solution: Prompt Caching
OpenAI employs a caching strategy similar to “prefix matching.”
In simple terms, as long as the first part of the content sent to the model (System instructions, tool definitions, historical dialogue) remains unchanged, the server does not need to recalculate and can directly retrieve from the cache.

This trick reduces the cost of long conversations from quadratic growth to linear growth.
However, there’s a catch: Any change to the Prompt prefix will invalidate the cache. For example:
- Switching models midway
- Modifying permission settings
- Changing the MCP tool list
The OpenAI team even admitted in the article that their early MCP tool integration had bugs: the order of the tool list was unstable, leading to frequent cache invalidation.
Pain Point 2: Limited Context Window
No matter how large the model, the context window is still limited.
If the Agent reads a huge log file, the context fills up quickly, causing earlier memories to be pushed out.
For programmers, this means: “Did you forget the function I defined earlier?!”
This is not just foolish; it’s disastrous.
Solution: Compaction
When the number of tokens exceeds a threshold, Codex does not simply “delete old messages”; instead, it calls a special /responses/compact interface to compress the conversation history into a shorter summary.

Regular summarization just shortens long text, losing a lot of details.
OpenAI’s Compaction returns a segment of encrypted_content, preserving the model’s “implicit understanding” of the original dialogue.
This is like compressing a thick book into a “memory card”; the model can recall the entire content of the book by reading the card.
This allows the Agent to maintain its “intelligence” when handling long tasks.
This time, OpenAI has revealed the “brain” behind Codex CLI and the “Agent Loop,” sending a signal: AI is truly ready to get the work done.
One Master Database Handling 800 Million Users
Extreme Operations of PostgreSQL
While everyone is discussing how powerful AI models are, OpenAI quietly exposed an even more explosive piece of news:
Supporting 800 million ChatGPT users and processing millions of queries per second is achieved with just a single master PostgreSQL database!
It only uses one PostgreSQL master node and 50 read replicas.

800 million users? This is almost unbelievable! Some netizens were astonished.
In an era dominated by distributed architectures, where many opt for “microservices,” “sharding,” and “NoSQL,” OpenAI shows that they can handle it with just PostgreSQL.

How did they achieve this?
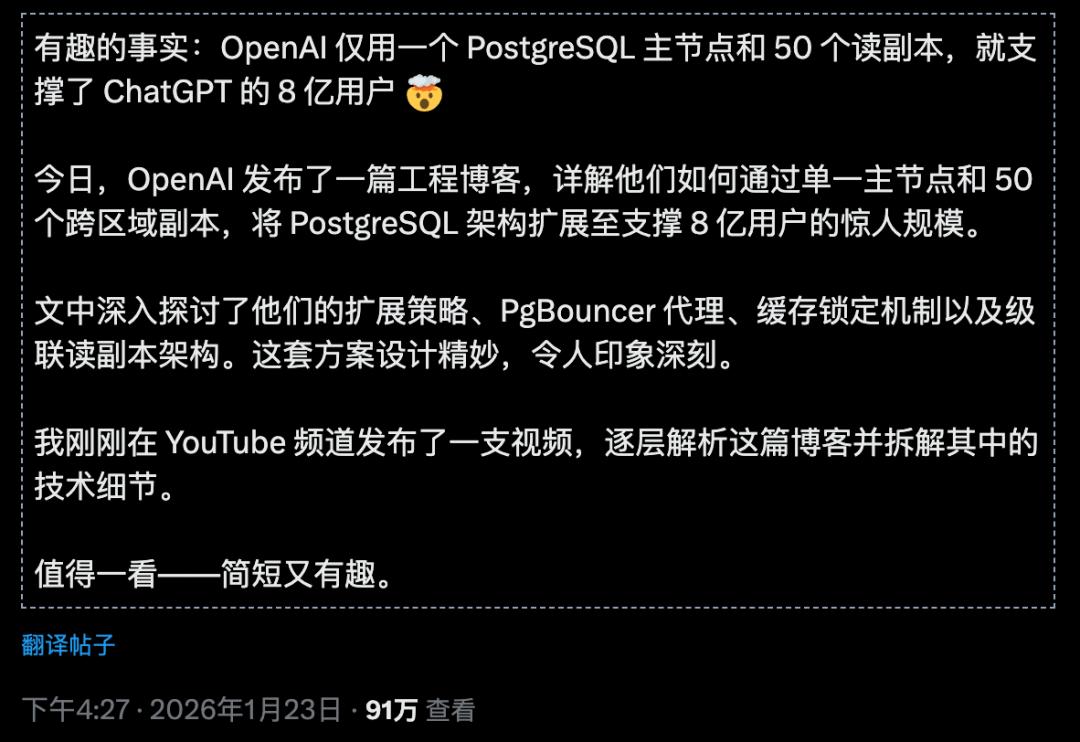
According to information disclosed by OpenAI engineers, key technologies include:
- PgBouncer connection pool proxy: Significantly reduces database connection overhead.
- Cache locking mechanism: Prevents write pressure caused by cache penetration.
- Cross-regional cascading replication: Distributes read requests to replicas around the globe.
The core idea of this architecture is: read-write separation, optimizing the read path to the extreme.
After all, for applications like ChatGPT, read requests far exceed write requests. When a user sends a message, the system may need to read data dozens of times (user information, conversation history, configuration information, etc.), but writing occurs only once.
According to OpenAI’s official blog, key technologies include:
1. Connection Pool Proxy (PgBouncer)
By managing the connection pool, the average connection establishment time was reduced from 50ms to 5ms.
Don’t underestimate this 45ms; in a scenario with millions of queries per second, this is a significant performance boost.
2. Cache Locking/Leasing Mechanism
This is a very clever design.
When the cache is not hit, only one request is allowed to query the database and refill the cache, while other requests wait.
This avoids the disaster scenario of “cache avalanche”—where a large number of requests simultaneously flood the database.
3. Query Optimization and Load Isolation
The team discovered and fixed a complex query involving 12 table joins.
They moved the complex logic to the application layer to avoid OLTP anti-pattern operations in the database.
Additionally, requests were divided into high-priority and low-priority, handled by dedicated instances to prevent performance degradation caused by the “noisy neighbor” effect.
4. High Availability and Failover
The master database operates in high availability (HA) mode, equipped with hot standby nodes.
All read traffic is directed to replicas, ensuring that even if the master database goes down, the service remains read-only available, reducing the impact of failures.
The Ceiling Will Eventually Be Reached
However, OpenAI also admits that this architecture has hit physical limits. The issues arise in two areas:
PostgreSQL’s MVCC Limitations
PostgreSQL’s Multi-Version Concurrency Control (MVCC) mechanism leads to write amplification (updating a row requires copying the entire row) and read amplification (scanning requires skipping dead tuples). This is a hard limitation for write-intensive loads.
WAL Replication Pressure
As the number of replicas increases, the master database must push the pre-written logs (WAL) to all replicas. The more replicas there are, the greater the network pressure on the master, and the higher the replica latency.
To overcome these limitations, OpenAI is doing two things:
- Migrating shardable, high-write loads to Azure Cosmos DB and other distributed systems.
- Testing cascading replication: allowing intermediate replicas to forward WAL to downstream replicas, aiming to support over 100 replicas.
This case perfectly illustrates an architectural philosophy: If not necessary, do not increase entities.
Don’t rush into distributed systems; first, use simple solutions to hold up, and only complicate when necessary.
Many companies face the problem of having overly complex architectures before they even reach the stage where distribution is needed. As a result, they neither gain the benefits of distribution nor avoid the complexities.
OpenAI proves through practice that an optimized single-node architecture can go further than one might imagine.

The Battle Between Codex and Claude Code
What is Claude Code’s killer feature? It is the end-to-end development experience.
It is not just a simple code completion tool; it is an Agent that can work independently in the terminal.
It can read code, modify code, run tests, handle Git, and even fix bugs on its own. Now it can even write documentation and create presentations.
This directly threatens the position of Codex CLI.
OpenAI’s recent updates actually convey three messages:
First, my Agent architecture is more mature.
The unveiling of the Agent Loop showcases OpenAI’s deep accumulation in Agent architecture. This is not a hastily assembled product but a carefully designed system.
Prompt Caching, Compaction, MCP tool integration… these are all solid engineering capabilities.
Second, my infrastructure is stronger.
The PostgreSQL case demonstrates OpenAI’s backend capabilities. The scale of 800 million users is not something just any startup can handle.
This also hints: our “moat” is not just the model but the entire engineering system.
Third, my model is becoming stronger.
The disclosure of cybersecurity ratings serves both as “expectation management,” informing everyone that the model has risks and that we are handling them responsibly, and as a show of strength: our model is now so powerful that it requires dedicated assessment of cybersecurity risks.
The competition in AI programming tools has only just begun.
Claude Code has forced OpenAI to accelerate the iteration speed of Codex. OpenAI’s response will, in turn, push Anthropic to continue innovating.
In the end, the beneficiaries will be us developers.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.